In today’s fast-paced life sciences environment, literature reviews are critical—but they’re also time-consuming, labor-intensive, and increasingly expected to support regulatory, HEOR, and market access submissions while maintaining full transparency and traceability.
While traditional platforms offer useful automation features, most are either rules-based classifiers or structured workflow tools, limiting their adaptability and explainability. That’s where MadeAi™ stands out.
By combining next-generation large language models (LLMs) with built-in human oversight (MadeAi’s seasoned AI-powered Services), MadeAi delivers a smarter, more flexible approach to evidence synthesis—purpose-built for teams who need speed, scale, and scientific integrity.
Two Smart Modes. One Flexible Framework.
MadeAi’s architecture supports two modes of AI integration, designed to meet users where they are in their digital and operational maturity:
1. AI-Aided Review
In this mode, the AI suggests article inclusion/exclusion decisions along with a clear rationale. Two blinded reviewers evaluate the AI’s suggestions independently, retaining full decision-making control.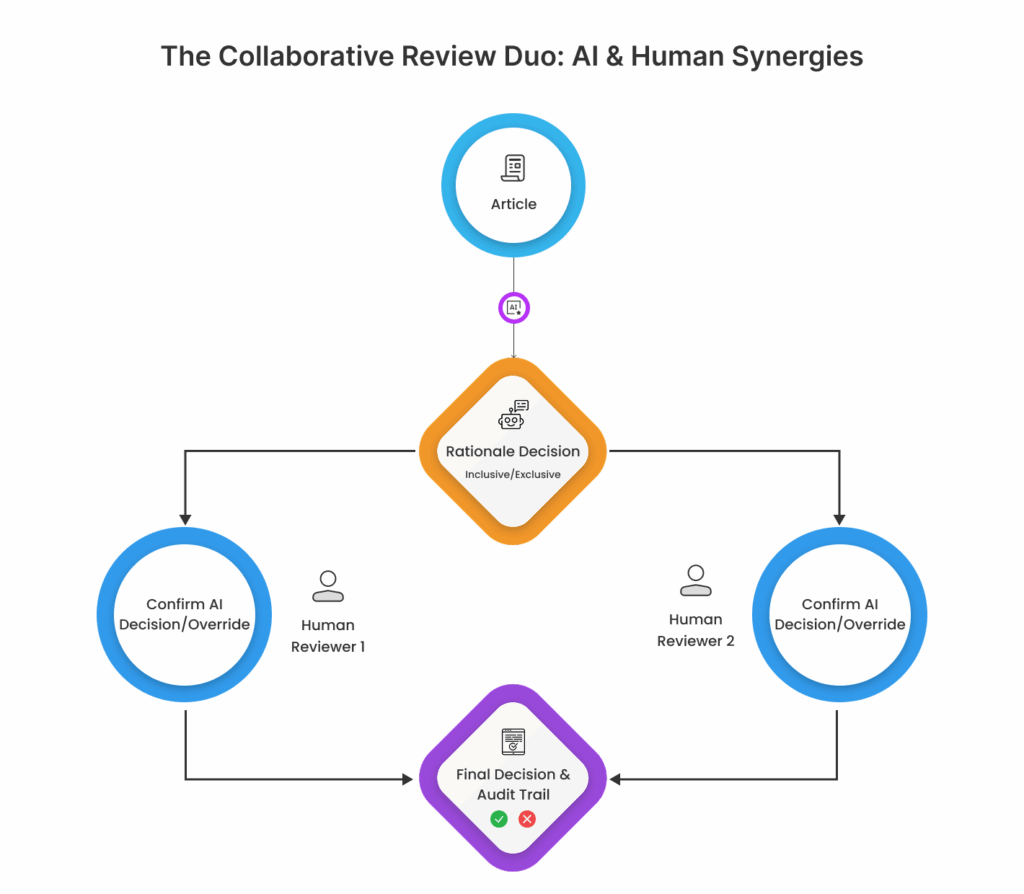
Ideal for teams that want:
- To prioritize high transparency and manual validation
- Early-phase evaluations or regulatory-compliant reviews (e.g., HTA, systematic reviews)
- Organizations new to AI-based workflows and want gradual adoption
- Reviews requiring two human decisions for quality assurance or methodological rigor
This hybrid model enhances both speed and reproducibility—particularly useful in contexts requiring regulatory defensibility.
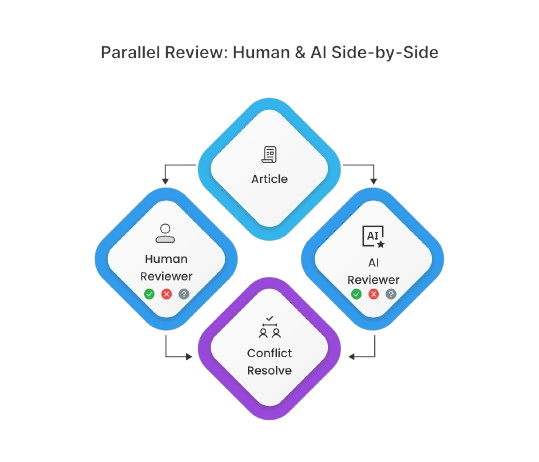
2. AI as Reviewer
For teams looking to reduce manual workload further, MadeAi can act as the second reviewer in dual-review screening. A human reviewer, who is blinded to the AI results, works in parallel with the AI, and disagreements can be flagged for adjudication.
The AI-aided approach is well-suited to support:
- Environments with high literature review volume
- Resource-constrained teams
- Instances when one human review is sufficient, and adjudication handles discrepancies
This model enables significant cost savings by reducing the need for a second human reviewer, while maintaining oversight and quality control—critical for regulated domains.
What Makes this Approach Different
Many legacy tools rely on predefined classifiers or rigid, structured review paths. MadeAi takes a fundamentally different approach by focusing on explainable GenAI and domain-informed customization. Key differentiators include:
- Transparent AI Output
Each decision is backed by a clear explanation, helping reviewers—and auditors—understand the reasoning. - Custom Prompt Engineering
Instead of using off-the-shelf models generically, MadeAi adapts its prompting and tagging to your review protocol (e.g., PICOS, eligibility criteria), improving both accuracy and relevance. - Workflow Flexibility
Whether you prefer full AI review, hybrid models, or phased integration, MadeAi is built to adapt—not disrupt. - Expert-Led Services
Backed by a team of literature review professionals, machine learning engineers, and medical writers, MadeAi isn’t just software—it’s a scalable partnership.
Designed for Life Sciences Teams
This isn’t a general-purpose NLP tool repackaged for pharma. MadeAi is built specifically for:
- HEOR and value evidence generation
- Clinical and regulatory literature review
- Real-world evidence teams managing high volumes of studies
In testing, clients have reported:
- Up to 60% reduction in screening time
- 90% AI-aided accuracy rates
- Stronger alignment with regulatory expectations
- Faster onboarding and shorter time-to-insight
Smarter. Faster. Fully Explainable.
Whether you’re evaluating your first AI solution or looking to upgrade from rigid tools, MadeAi offers the transparency, flexibility, and speed today’s life sciences teams need. It’s GenAI built with real-world reviewers in mind.
Ready to rethink your approach to literature review?
Schedule a demo and discover how MadeAi helps teams work faster—without compromising what matters most.

