Though many organizations see the value of AI in literature reviews and evidence generation, not all can adopt AI in the same way.
Some teams are ready for a web-based SaaS solution. While others, especially large pharma and regulated enterprises, face internal AI policy barriers, data residency requirements, and IT constraints that make SaaS adoption difficult, even when there is clear demand. When implemented effectively, AI can significantly reduce review timelines, improve consistency, and strengthen traceability across evidence workflows.
Yet for organizations operating in stringently regulated environments—such as pharma, biotech, and healthcare—AI adoption often stalls. The challenge isn’t whether AI works, but whether it fits within existing regulatory, quality, and governance frameworks.
Why AI Adoption Stalls in Regulated Settings
Traditional AI deployments, particularly SaaS-based models, raise legitimate concerns for regulated teams. These include data residency and privacy, validation and auditability, change control, and long-term operational risk. Even high-performing AI tools can fall short if they cannot align with GxP expectations, ALCOA+ data integrity principles, or internal quality systems. As a result, many organizations delay adoption—missing out on clear efficiency and quality gains. However, there is an approach that could mitigate these barriers to adoption. However, there is an approach that could mitigate these barriers to adoption.
Consider the Build–Run–Own Model
The Build–Run–Own model offers a structured alternative designed specifically for regulated, evidence-driven environments. Rather than treating AI as a black-box tool, this approach enables organizations to adopt AI as a controlled, validated, and ultimately owned capability.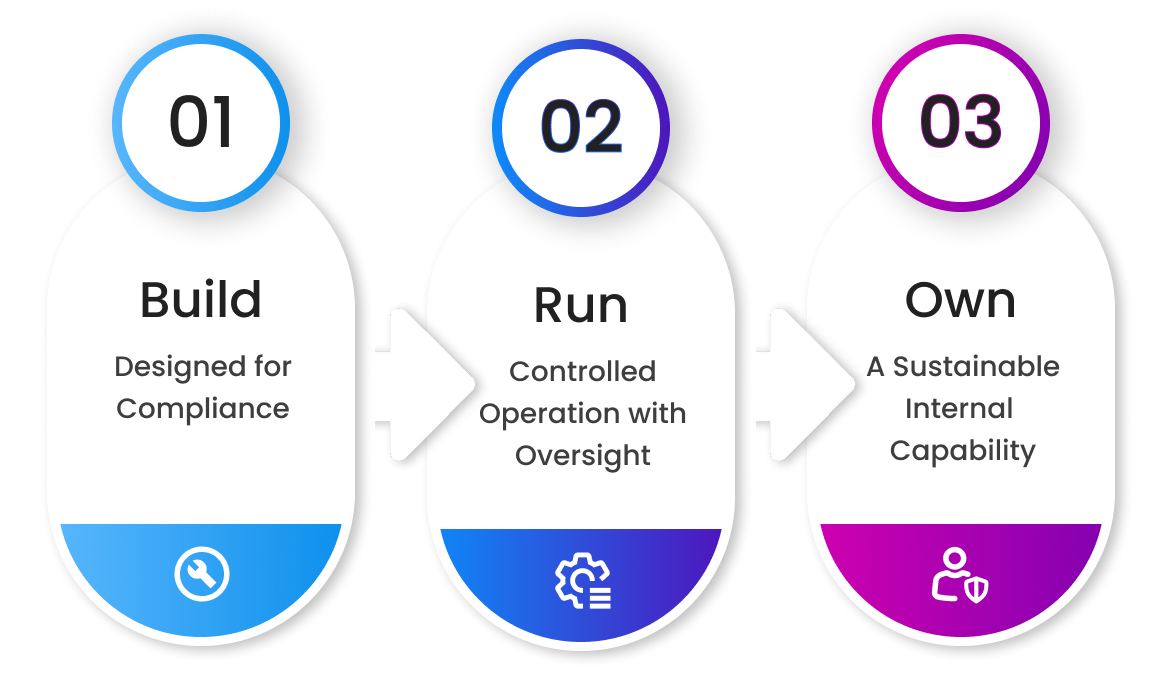
Phase 1: Build—Designed for Compliance
In the Build phase, AI systems are configured to align with existing SOPs, literature review methodologies, and IT and quality frameworks. This includes meeting data integrity, security, access control, and deployment requirements—often within private or on-premise environments.
The goal is to ensure the AI fits the regulatory context from day one.
Phase 2: Run—Controlled Operation with Oversight
During the Run phase, the AI system is used operationally under joint oversight from AI specialists and internal scientific and quality teams. Performance is monitored, validation evidence is generated, and governance and change control processes are established.
This phase allows organizations to realize real-world value while maintaining regulatory confidence.
Phase 3: Own—A Sustainable Internal Capability
In the Own phase, full operational responsibility transitions to the organization. AI workflows are integrated into quality management systems and regulatory submission processes, and internal teams manage updates, validation, and ongoing use.
At this point, AI becomes a durable, compliant capability—not a dependency on an external vendor.
Why This Model Works
The Build–Run–Own approach reduces regulatory risk while enabling speed, transparency, and long-term control. It supports validation readiness, preserves data ownership, and helps organizations develop internal expertise over time.
Most importantly, it aligns AI innovation with the realities of regulated evidence generation.
Final Thought
For life sciences organizations, successful AI adoption isn’t about moving fast at any cost—it’s about moving forward responsibly. The Build–Run–Own model provides a practical, compliant path to AI-driven literature reviews, enabling teams to innovate with confidence while meeting the highest regulatory standards.

